KL divergence(KL 散度)
KL散度(Kullback-Leibler (KL) divergence)通常用来衡量两个单独的概率分布的差异,设对于同一随机变量的两个概率分布为P(x)和Q(x),则它们的KL散度定义为:
DKL(p∣∣q)=Ex∼P[logP(x)−logQ(x)]
KL散度具有的性质有:
- 非负:要使得KL散度为0,当且仅当P(x)和Q(x)是在离散型变量的情况下是相同的分布,或者在连续型变量的情况下是“几乎处处”相同的[1]。
- 非对称:对某些P(x)和Q(x),KL散度和逆KL散度通常并不相等,也就是DKL(P∣∣Q)=DKL(Q∣∣P)。
本文将从三个角度分析KL散度的非对称性:直观看法,理论说明,计算实验。
KL散度的非对称性
直观看法
假设在问题中,我们已知某种分布P(x),我们希望使用分布Q(x)来近似P(x)。在这里我们为了说明问题的简便性,我们假定P(x)为由两个高斯分布混合得到的高斯混合模型,而Q(x)为高斯分布,两种KL散度定义为:
DKL(p∣∣q)=Ex∼P[logP(x)−logQ(x)]
DKL(q∣∣p)=Ex∼Q[logQ(x)−logP(x)]
KL散度描述了在已知的分布上,函数logP(x)−logQ(x)的期望。已知的高斯混合分布模型具有两个峰,优化KL散度,Q(x)只有单峰,它就必须要在这两个峰上的值偏小,并且还要保证中间的单峰和P(x)偏差不会太大,所以它会模糊地将多个峰聚合在一起,并且贴合P(x),也就是单个高斯分布的σ2会偏大。
而逆KL散度描述了在未知的分布上,函数logQ(x)−logP(x)的期望。Q(x)仅有单峰,它必须贴合某个峰,而在另外一个峰的值足够的小(这样它在另一个峰的期望会很小),所以它会选择单个峰,并且使得σ2偏小。
下面我们将从理论和数值实验上对KL散度的非对称性做进一步的说明。
理论说明
假设混合高斯分布模型由两个单高斯条件分布按概率p1,p2混合而成
两个单高斯条件分布为:
X1∼N(μ1,σ12)
X2∼N(μ2,σ22)
假设它们的概率密度函数分别为p1(x)和p2(x),则混合高斯模型的概率密度函数可以表示为:
p(x)=p1p1(x)+p2p2(x)
该混合高斯模型是给定的,参数p1,p2,μ1,μ2,σ12,σ22都是已知的
常数。
现在使用单高斯分布模型来近似p(x),假设它的均值和方差为μ和σ2,它的
概率密度函数为:
q(x)=2πσ1e(−2σ2(x−μ)2)
KL散度的情况下
(1) 在第一种KL散度DKL(p∣∣q)作为衡量单高斯分布模型拟合
混合高斯分布模型的近似程度的的情况下。
DKL(p∣∣q)=Ex∼p[logp(x)−logq(x)]=∫[logp(x)−logq(x)]p(x)dx=∫[logp(x)]p(x)dx−∫[logq(x)]p(x)dx
上式的左项为常数,要使得DKL最小,右项要取得最大值,令右项为L。
L=∫[logq(x)]p(x)dx=∫log(2πσ1e(−2σ2(x−μ)2))p(x)dx=∫(−log2π−logσ−2σ21(x−μ)2)p(x)dx=−log2π−logσ−2σ21∫(x−μ)2p(x)dx
令T=∫(x−μ)2p(x)dx,L要取得最大值,T要取得最小值。
T=∫(x2−2μx+μ2)p(x)dx=∫x2p(x)dx−2μ∫xp(x)dx+μ2∫p(x)dx
则L对μ的导数为:
∂μ∂L=∂T∂L∂μ∂T=−2σ21(2μ−2∫xp(x)dx)=0
求得最优解μ0:
μ0=∫xp(x)dx=p1∫xp1(x)dx+p2∫xp2(x)dx=p1μ1+p2μ2
此时T取得最小值,
而L对σ的导数为:
∂σ∂L=−σ1+σ3T=σ1(σ2T−1)=0
得最优解σ0:
σ02=T=p1∫x2p1(x)dx+p2∫x2p2(x)dx−2μ02+μ02=p1(σ12+μ12)+p2(σ22+μ22)−(p1μ1+p2μ2)2
可以看到当取得最优解的时候,μ0是混合高斯模型的两个条件分布模型的均值的期望,而且
μ1≤μ0=p1μ1+p2μ2≤μ2,说明此时的最佳
拟合的单高斯分布选择是将混合高斯模型的多个峰值聚合起来。
逆KL散度情况下
(2) 在第二种KL散度DKL(q∣∣p)作为衡量单高斯分布模型拟合混合高
斯分布模型的近似程度的的情况下。
DKL(q∣∣p)=Ex∼q[logq(x)−logp(x)]=∫[logq(x)−logp(x)]q(x)dx=∫(logq(x))q(x)dx−∫(logp(x))q(x)dx
令A=∫(logq(x))q(x)dx,B=∫(logp(x))q(x)dx,要使得
DKL(q∣∣p)取得最小值,A要取得最大值,B要取得最小值。
A=∫(logq(x))q(x)dx=∫−log2π−logσ−2σ2(x−μ)2q(x)dx=−log2π−logσ−2σ21∫(x−μ)2q(x)dx=−log2π−logσ−21
可以看到A的取值和μ无关。
B=∫(logp(x))q(x)dx=∫log[p1p1(x)+p2p2(x)]q(x)dx=∫log[p1p1(x)]q(x)dx+∫log[1+p1p1(x)p2p2(x)]q(x)dx
令B1=∫log[p1p1(x)]q(x)dx,B2=∫log[1+p1p1(x)p2p2(x)]q(x)dx
B1=logp1+∫[logp1(x)]q(x)dx=logp1−log((2π))−logσ1−2σ121∫(x−μ1)2q(x)dx=logp1−log((2π))−logσ1−2σ121(μ2+σ2−2μ1μ+μ12)
B1是关于μ的二次函数,当μ=μ1时,B1取得最大值。
B2=∫log[1+p1p1(x)p2p2(x)]q(x)dx<∫p1p1(x)p2p2(x)q(x)dx=p1p2∫σ11e−2σ12(x−μ1)2σ21e−2σ22(x−μ2)22πσ1e−2σ2(x−μ)2dx=p1σ2p2σ12πσ11∫e2σ12(x−μ1)2−2σ22(x−μ2)2−2σ2(x−μ)2dx
如果我们取使得B1为最大值的μ=μ1,并使得σ=σ1,此时
B2<p1σ2p2σ12πσ11∫e−2σ22(x−μ2)2=p1σ2p2σ12πσ112πσ2∫p2(x)dx=p1p2
即此时有B2<p1p2,如果p2≪p1,那么B2接近于0,我们就可以忽略该项,那
我们选取μ=μ1就是最优值。
同理如果我们在得到B推导的最后一步,将B拆解为:
B=∫log[p2p2(x)]q(x)dx+∫log[1+p2p2(x)p1p1(x)]q(x)dx=B1′+B2′
我们可以得到,当p1≪p2时,我们选取μ=μ2就是最优解。
而这两种拆分的方式只是依据p1,p2的大小而定,它们是等价的,我们假定当p2<p1时使用第一种拆分方式,
当p1<p2时使用第二种拆分方式,并令它们的比值为k,那么当p1=p2时,k取得最大值为1。
也就是说B2≤1,它总是可忽略的。
综上所述,使用第二种KL散度作为作为衡量单高斯分布模型拟合混合高斯分布模型的近似程度的情况下,单个高斯分布模型会倾向于偏向p更大的混合概率模型中的单峰。
计算实验
我们使用数值模拟的方法求解给定的混合高斯模型的单个高斯模型近似的μ和σ2的最优解。
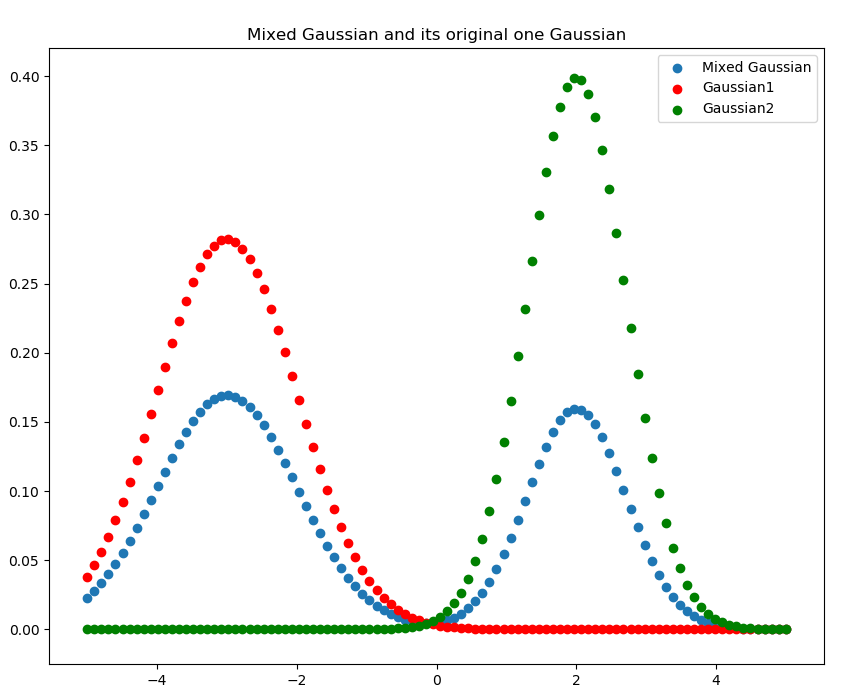
给定混合高斯模型X=p1X1+p2X2。
其中p1=0.6,p2=0.4,X1∼N(−3,2),X2∼N(2,1)
概率密度函数如下图所示。
混合高斯模型概率密度函数图像
KL散度情况下
使用KL散度作为衡量单高斯分布模型拟合混合高斯分布模型的近似程度的情况下
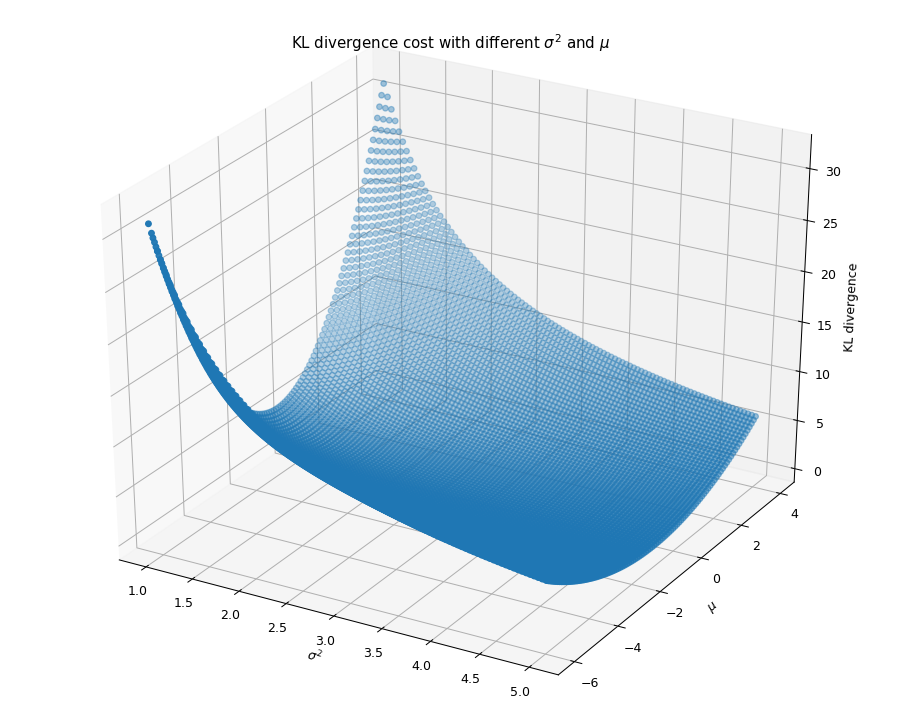
下图给出了KL散度和不同σ2,μ取值的二元函数的图像,
我们发现该二元函数比较平滑。
KL散度和不同${sigma^{2},mu}$取值的二元函数的图像
给定初始值μ=1,σ2=1使用梯度下降公式迭代求得
最优解为:μ=−0.99966166,σ2=6.45287537。
这与我们计算得到的μ=p1μ1+p2μ2的公式吻合。
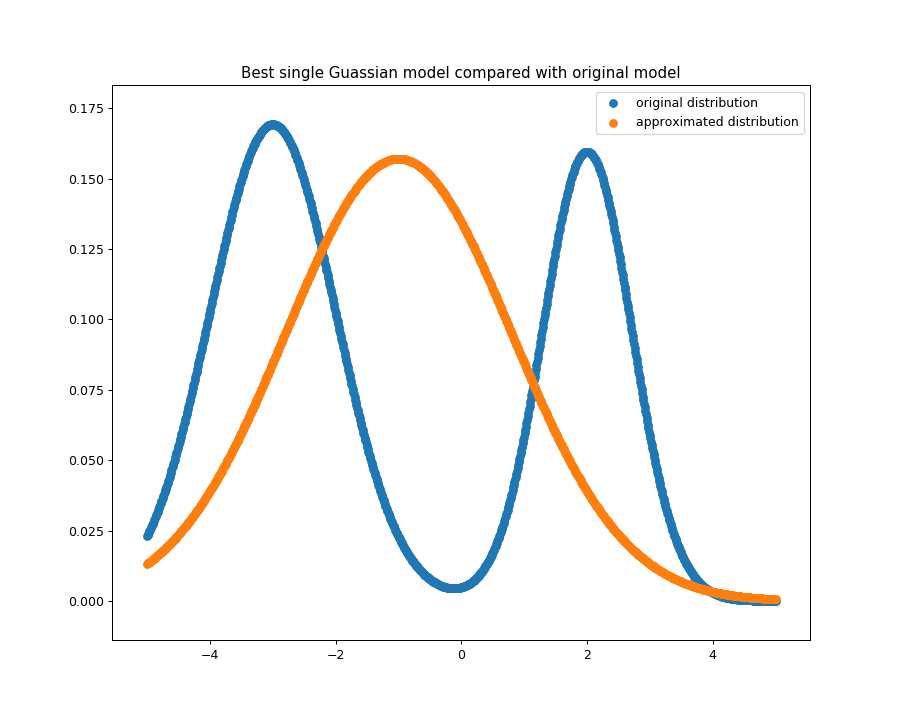
我们画出得到的最佳的高斯分布的图像如下图所示,单个的高斯分布模型模糊地将
混合高斯模型的几个峰模糊地聚合了起来。
KL散度下最佳单个高斯分布模型
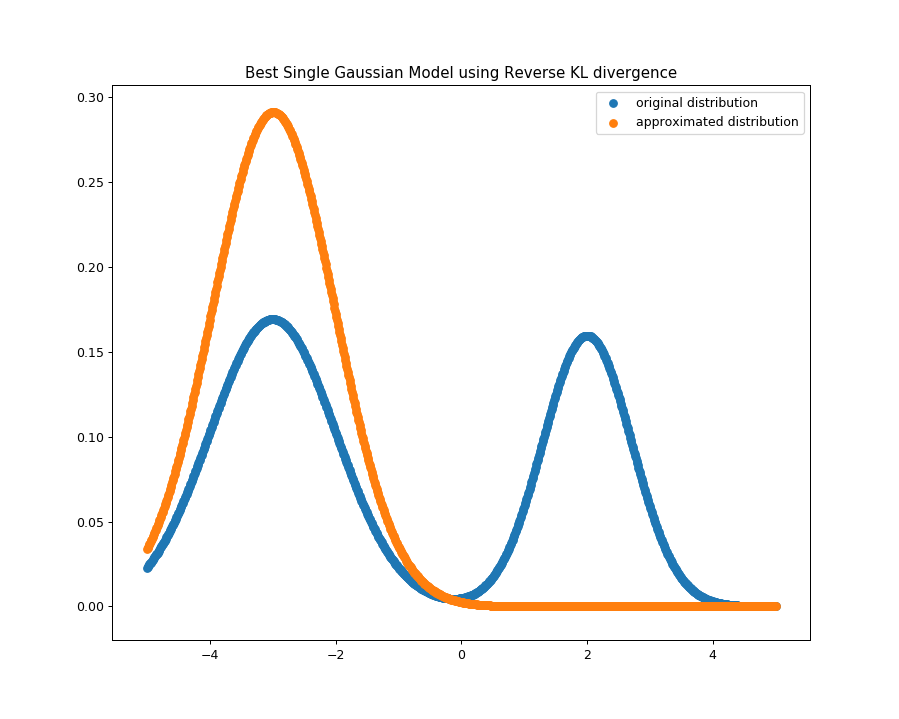
逆KL散度情况下
使用逆KL散度作为衡量单高斯分布模型拟合混合高斯分布模型的近似程度的的情况下
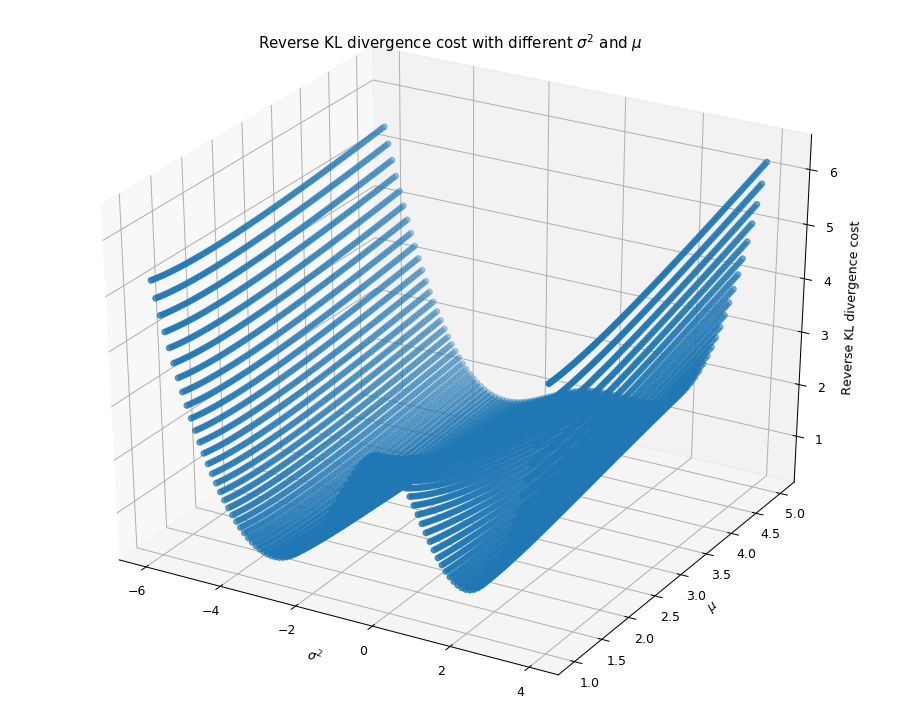
下图给出了逆KL散度和不同σ2,μ取值的二元函数的图像,
同样的我们发现该二元函数也比较平滑。
KL散度与不同的${sigma^{2}}$和${mu}$取值的关系
给定初始值μ=−1,σ2=1使用梯度下降公式迭代求得
最优解为:μ=−2.98863212,σ2=1.87676299,这也与我们理论推导的结论相吻合。
此时得到的单个高斯分布模型的图像如下图所示,我们看到该高斯分布会选择概率比较大的峰拟合。
逆KL散度下最佳的单个高斯分布模型
实验的代码将发布在我的github上。
实验细节:
- 使用Simpson公式计算KL散度中连续性变量的期望的积分,而且在我们给定的高斯分布下,处于区间[−20,20]之外的值的概率密度是非常小的,所以我们将积分的上下限替换为20和-20,而不是正负无穷。
- 我们使用梯度下降法求解最优的参数。
- 在梯度下降法中,我们使用中心差商公式来求得梯度,虽然使用数值方法计算梯度的做法非常不好,但是本次实验中两种KL散度的cost函数比较光滑,所以数值计算的结果也可以比较精确。