本文是对"on the steerabilty of generative adversarial networks"[2]一文的学习。
Introduction
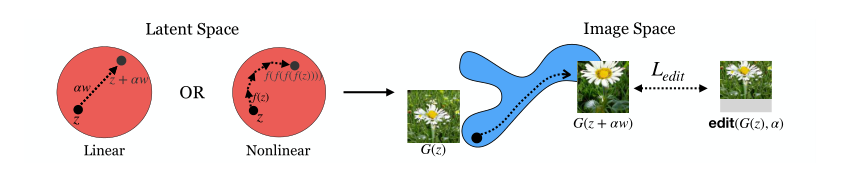
研究的问题阐述:对latent space的隐变量进行移动得到,使得GAN生成的图片是原来生成的图片通过某种变换之后得到的图片,本文提出了线性和非线性两种移动方法。
本文研究的变换包括:
- 颜色变换。
- 目标物体的放大和缩小。
- 左右上下移动。
- 旋转变化。
Methods
主要包含三个部分的内容:
- 构造 的方法,分为线性和非线性两种。
- 对生成图像的变换效果量化。
- 提出两种降低该方法的限制的方法。
Methods of walking latent space
线性方法:对给定的目标图片的变换,希望学习到一个N维向量:
(在这里是一个累加步的意思,其实在公式中使用会不会更加 make sense,这样学习的就仅仅是变换的方向,不过确实除了方向还要学习大小,但是我确实感觉这里又有一个比较多余,没有完全分开大小和方向。)
其中表示变换的大小,又对应在隐空间中移动的程度;表示原始隐变量{z}$生成的图片。
整个公式可以理解为:操作累加得到,生成图片。原始生成图片经过对应程度的变换得到图片。
优化的目标就是和距离的期望最小。在文章中使用L2距离。
非线性的方法: 目标改变成学习一个非线性映射,它将latent space 上的点映射成另一个点。对原始的进行多次映射要对应地对目标的图片进行多次的变换,最佳的非线性映射表达式:
在这里可以用一个前馈神经网络来近似。两种方法的直观解释如图1所示。
作者还提到使用 的形式,容易导致将等式右边的项忽略。(有点不明白,可能需要进一步的实验验证。)
量化steerability的效果
这里作者主要谈及如何对 walk latent space 的方法进行评价,对不同的目标tranformation有不同的评价方法,评价方法主要和如何对训练集进行transformation有关。
-
颜色变换:对训练集的颜色变换是调整RGB通道的系数,对每张生成图片和walk后生成的图片,随机采样一百个像素,取每个通道改变的均值。
-
放大缩小、位移变换:作者使用了一个 MobileNet-SSD 用于检测主要物体的位置。如果成功检测到物体,提取对应的正确标签的 bounding box。bounding box 的面积和整体image的比例用于评价放大缩小的效果。bounding box 的中心(X,Y)位置之差除以图片的整体尺寸用于评价位移效果。
减少这种方法的限制
对这种方法确实存在一定的限制,作者猜想**这种限制来源于数据集(如果GAN在数据集中没有见过类似变换后的图像,GAN很难生成可以满足这种变换的图像)**为了提高 latent space 的操作性,进一步提出了两种在训练中使用的方法。
-
数据增强:可以使得 GAN 能学习到不同视角、变换后的图片。
-
修改训练的损失函数,添加,同时对增加步和生成器进行优化。
是一种修改过后的WGAN Loss。
实验和结论
作者设计了一系列的实验:
- 实验1: Image Transform Limitation
作者发现问题:
- 对涉及的几种变形都观察到:当继续增大变形比例时,模型不能生成比较真实的图像了,或者增大比例时生成图像的变形比例不变(存在允许的变形范围)。
- 同一种变换对不同class的物体的作用影响不一样(有的可以成功将物体颜色改变,有的只有稍微改变)。
针对这一现象,作者提出假设:该现象的引起源于数据集中不同类的多样性。比如数据集中基本上不会出现蓝色的消防车,所以对消防车的变色效果很差。
- 实验2:How does the data affect the transformations
作者设计了实验说明上一个实验的假设,提出:如果不同的类有不同的变形限度是因为不同类的多样性问题,那么类的变形限度和该类图片的标准差存在关系。
记表示对原latent space移动大小再经过生成器得到的图片分布,类变形限度用最大和最小变形的图片均值表示,对第个类,这一公式表示为:
是训练中使用的最大系数(同时保持比较低的FID)。
实验观察到它和类图片的标准差存在相关性,说明了实验一中的假设。
- 实验3:Comparison between linear way and non-linear way
实验现象:Linear方法虽然transform的比例不大,但是图片比较真实;相反,non-linear方法transform的比例更加好,但是不够真实。
作者观点:
- 生成图像的真实性和transform的比例是trade-off。
- linear方法和latent space内部结构比较贴合。
- 实验4:Limitation Reduced Methods
实验观察得到的结论:
- “不加数据增强” 劣于 “数据增强” 劣于 “数据增强 + 联合训练”。
- 在 DCGAN trained on CIFAR10上,三种方法都失效了。
复现尝试
基于以上的方法做了一个小小的复现:
(1) 数据集: MNIST(经过数据增强,包含Zoom和Center Shift)。
(2) GAN:使用 DCGAN 的架构,对判别器使用spectral normalization[1],使用 Vanilla GAN Loss 和类似ACGAN的分类Loss[3]训练。
(3) 使用文中的线性方法。
结果(只针对Zoom变换,并等差地取64个变换等级):
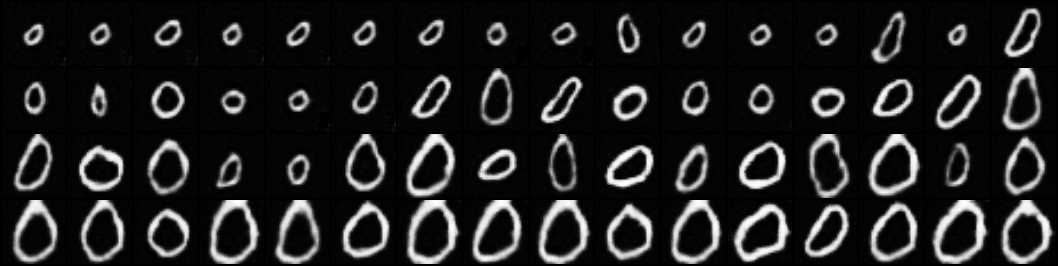

训练的时间不长,也没有细调参数,但是还是一定程度上达到了引导Zoom变换的效果,如图2所示。
评价
首先,本篇文章在GAN的latent space的探索上迈进了一步。作者成功在latent space上引导GAN生成的经过某些指定修改的图片。
主要的贡献的在于:
- 提出了线性和非线性的方法引导。
- 分析这种方法的limitation源于数据集各类图片的多样性。
- 提出了两种降低limitation的方法:(1) 数据增强,手动
提高图片多样性;(2) 修改损失函数,同步训练。
Future Work
- 更好的reduce limitation的方法:
作者提到,对在CIFAR10上训练的DCGAN,两种降低limitation的方法都失效了。而且作者认为transform limitation和图片的质量是trade-off。
- 更加generalized的引导方法:
作者提出的方法是 transform specified,能否设计一个对更多的变换都有效的方法,或者更加统一的方法。
- latent space 分析:
基于以上的方法,可以对latent space的性质展开更多的分析,比如latent space的线性结构等。
Reference
-
Takeru Miyato, Toshiki Kataoka, Masanori Koyama and Yuichi Yoshida. Spectral normalization for generative adversarial networks. 2018
-
Ali Jahanian, Lucy Chai and Phillip Isola. On the “steerability” of generative adversarial networks. 2019
-
Augustus Odena, Christopher Olah and Jonathon Shlens. Conditional image synthesis with auxiliary classifier gans. 2017