本文是对"Interpreting the Latent Space of GANs for Semantic Face Editing. [paper] [codes]"[2]一文的学习。
Introduction
本文研究的问题是:在latent space上修改输入噪声,操作GAN生成的图像不同语义。
本文的工作都基于以下假设:
Assumption 1:
对任意一维线性变化的语义,存在 latant space 上的分类超平面可以分离他们的极端值。
基于原文的意思,这个假设应该是最合理的。
FrameWork
一个well-trained的GAN学习隐空间(通常是多元标准正态分布)到图像流形的映射。
加入一个语义评分(semantic scoring)函数,这个函数表示了图像的表示某种语义的程度。
Property 1:
对任意向量,且,集合{\left\\{\mathbf{z} \in \mathbb{R}^{d}: \mathbf{n}^{T} \mathbf{z} = 0\right\\}}定义了一个上的一个超平面,对任意的向量,的所有点位于超平面的同一侧。
Property 2:
对任意,且,若隐空间,对任意:
成立,其中为常数。
Property2就是想说明大部分的latent space内的点都在由决定的超平面的附近。
Single Semantic
基于假设1,如果我们想改变某一种语义,只要移动latent code使之越过该语义属性在latent space上的超平面即可。由Property1,一个线性超平面可以由向量确定(且是单位向量,)。(注:Property1中确定的超平面显然经过,虽然文章没有提及,但是由于我们一般取噪声,所以可以理解)
任意一个latent space上的点到该超平面的距离为:
我们希望latent code到超平面的距离与它生成图片包含的对应语义属性的语义性成正比:
其中为超参数,这样我们可以用一个单位向量表示一种语义,而且可以在latent space上就可以直接衡量生成的图片的语义性。
Multiple Semantic
针对多种复合语义性的衡量可以用类似的方法,用表示不同的语义超平面法向量,多个语义属性的语义性强弱可以表示为:
其中,为对角阵(不希望语义重叠),同时可得的均值和方差:
可得。当且仅当为对角阵时,衡量的语义属性都是disentangled的,因为此时向量组正交。如果不为对角阵,可以衡量两个属性的entanglement的大小。
Manipulation
Single Manipulation: 现在我们能直接在latent space上衡量语义性,要操作latent code生成的图片的语义性就很简单了,对单个语义,只要沿法向量方向移动就行:
增强语义性,减弱甚至更改语义性。
除此之外,作者提出了对多个entangled的属性操作的方法(Conditional Manipulation)。
Conditional Manipulation: 假设两个语义属性s1,s2是entangled的,它们分别对应法向量,此时要使得改变语义属性s1,而不改变s2,可以沿着移动,如图12所示。
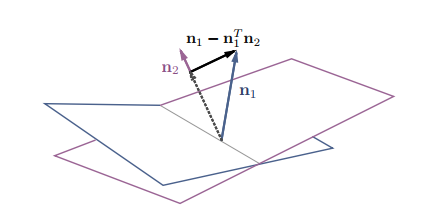
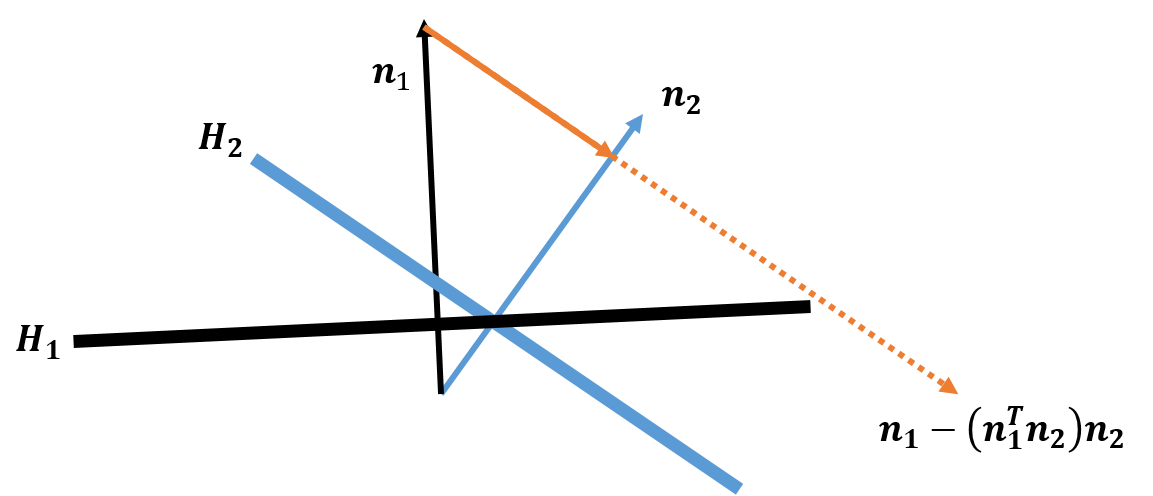
可以看到,也沿着方向移动就是沿着的超平面平行的方向,穿过的超平面。
对多个entangled的属性而要只改变其中一个,作者提出用相同的方法:减去所有其他entangled属性的法向量。(注:这里作者原文为"If there is more than one attribute to be conditioned on, we just subtract the projection from the primal direction onto the plane that is constructed by all conditioned directions."我觉得没有说的很清楚,猜测应该是和两个属性entangled的方法一致。)
Real Image Manipulation: 作者进一步扩展到真实图片的编辑,只要将真实图片通过某种方法映射到latent space上,再移动,最后再通过GAN生成即可。
Experiments
作者主要围绕PGGAN[1]和StyleGAN[3]两种模型进行实验。
- 实验1. Check if the assumption is right.
对不同的单个语义的图片,在latent space上训练Linear SVM,计算验证集和整个集合上的分类正确率,在不同语义上的实验都取得了比较高的分类正确率,所以一定程度上验证了线性可分的假设。
- 实验2. Latent Space Manipulation.
(1) Single Attribute Manipulation. (2) Distance Effect: 作者观察到,当移动样本距离超平面过远(大于给定值)时,生成的图片不真实。但是服从的噪声中很难采样到那么远的噪声,所以没关系。(3) Artifacts Correction: 作者将生成质量的好与坏也作为一对语义信息,学习超平面,将生成质量不好的图片变成好的图片。
- 实验3. Conditional Manipulation
(1) Correlation between Attributes. 本节作者提出了两种衡量语义属性相关性的方法,一是两属性的法向量的余弦相似度,二是将attribute score看成随机变量,随机采样并计算它们的Pearson相关系数。两种方法的效果差不多。
(注:这里的怎么计算?)在研究的五种语义属性中,发现年龄,性别,是否戴眼镜三个属性具有较强的相关性,姿势和笑脸属性和其他属性比较不相关。这反映了数据集中属性的倾向。
(2) Conditional Result. 展示了下结果。
- 实验4. StyleGAN
本节作者在StyleGAN的 latent space和 latent space进行实验,发现:(1) latent space 的效果更好,长距离的变化显著, latent space比 latent space更加disentangled(这和StyleGAN原论文的结论一致)
(2) Conditional Manipulation的方法在 latent space上失效了,作者将原因归结于 latent space中已经包含了融合特征
(如eyeglasses-age)的法向量,而且它和单个特征(如eyeglasses)的法向量是正交的,减去投影几乎不改变法向量,所以没有影响。
- 实验5. Real Image Manipulation
作者将真实图片通过InverseGAN的方法变换到latent space,在latent space上操作,再通过GAN可以对真实图片的属性进行修改。作者使用了两种Inverse GAN的方法:基于优化的方法和Encoder-based的方法。InverseGAN 的方法在PGGAN上效果差(作者认为是训练集和真实图像差异太大的原因),而在StyleGAN上成功。
Implementation Details
- normal vector
首先在数据集上预训练一个分类的网络,预测各属性的得分。随机生成500K个图像,对每张图像得到各个属性得分,对每个属性,选取得分最高的10K图像和最低的10K图像(为了避免中间的属性),取70%作为训练集,30%作为测试集,训练Linear SVM对latent codes分类,得到分类超平面,
得到法向量,并归一化。
但是作者也提到了由于预训练的分类网络不能完全分类准确,学习到的法向量不一定准确,对属性的entanglement性有一定的影响。
质疑
- 扩展性
为什么作者没有进一步把方法扩展到BigGAN?我觉得CelebA-HQ、FF-HQ数据集有很强的连续性,而且在之上训练的StyleGAN,PGGAN效果很好,如作者所言,模型本身已经学习了一些disentangled
representation,所以效果好的本身可能是由于StyleGAN本身已经很好。假设1成立建立在GAN已经训练地很好的基础上。
- StyleGAN实验问题
实验3.4中作者指出decorrelate的方法对StyleGAN的 Space不起作用,原因是StyleGAN已经学习到融合特征的direction(比如说eyeglasses-age),而且 eyeglasses-age direction 和 eyeglasses direction 正交,但是这两个方向可能正交(没有关联)吗?
- Conditional Manipulation存在的问题
如果根据线性假设1,那么如果存在超过两个以上的语义属性是entangled的,变化限度不限的情况下,不可能存在方向,使得沿着改变只改变一个语义属性,而保留其他语义属性不变。而且作者没有过多地对超过两个以上entangled的语义属性做实验(仅在Fig8中展示了一个三个属性entangled的结果),这是一个不足的地方。
原来我提出的关于Disentangled方法无效的说法是错误的,给出的例子是在二维空间中引入三种属性的法向量,但是这样存在维度的entangled。但是这也说明需要要大于desired的属性的数量才能保证可以disentangle。
除此之外如果两个属性非常相关,那么需要比较大的距离移动才能改变一个语义属性,同时保持另一个不变。但是过大的距离又可能导致图片失真。
所以Conditional Manipulation方法需要进一步的改进。
- 写作方面,我认为:
(1)作者在理论部分阐述地过多,而且提出的semantic score function等一些概念公式其实几乎没什么作用,十分鸡肋。文章理论部分最重要的部分在于假设,其次是Conditional Manipulation。
(2) 对于法向量的计算细节,作者只是在附录中提及,我觉得这个是非常重要的实现细节,应当放置在理论部分之后,实验部分之前。
评价和启发
文章的亮点在于:提出并近似地验证了假设1,通过假设可以直接在隐空间内衡量某种语义性的大小,然后只要按照方向移动操作生成图像的语义性。
文章给出了一种隐空间语义性的描述方法,但是并没有解决disentangled的问题,对多个disentangled的属性,仍不能很好地只对其中的一个进行改变。对我的启发是:如果文章对隐空间的描述正确的话,多属性的disentangled问题很难在空间内解决,类似StyleGAN的做法,将空间投影到空间,再从到图像,在上操作语义是更好的做法。
Reference
- Tero Karras, Timo Aila, Samuli Laine and Jaakko Lehtinen. Progressive growing of GANs for improved quality, stability, and variation. 2018…
- Yujun Shen, Jinjin Gu, Xiaoou Tang and Bolei Zhou. Interpreting the Latent Space of GANs for Semantic Face Editing. 2019.
- Tero Karras, Samuli Laine and Timo Aila. A style-based generator architecture for generative adversarial networks. 2019.