Preface
A Paper A day Keep the Doctor Away。 今天的文章是:
Dreaming to Distill: Data-free Knowledge Transfer via DeepInversion. (CVPR2020 Oral). [paper]
本文针对的问题是:从预训练的CNN中生成高质量的自然图像,并使用合成图像对预训练的CNN进行蒸馏,实现Data-Free的相关应用,主要内容包括:
- DeepInversion(DI):
DeepDream的基础上,改进DeepDream的正则化项,提高生成图像的质量的方法。 - AdaptiveDeepInversion(ADI): DI 的基础上,引入蒸馏子网和图像生成两个过程的竞争,进一步提高生成图像的多样性方法。
- Data-Free 应用,包括:
- Data-Free Pruning
- Data-Free Knowledge Transfer
- Data-Free Continual Learning
Main Contents
DeepInversions
DeepInversons方法基于DeepDream,在它的正则化项基础上,添加了feature map 层面约束:合成图像和训练图像的feature map统计特征相近。
作者将统计特征取为均值和方差,并用BN层的running_mean和runing_var替代训练集图像的统计特征,就不需要训练集图像了。(作者也提到如果模型中没有BN层,使用训练集的数据计算feature map的均值和方差也可以,并且实验中取1000个样本就和原方法效果差不多了。)
给定随机初始化的图像和指定的label,图像生成过程可以通过求解以下优化问题:
其中为分类loss(交叉熵),而为图像质量的正则化约束。DeepDream将该正则化项定义为TV和l2范数:
DeepInversion在该项的基础上,添加了合成图像和训练集图像feature map的统计约束,假定feature map服从高斯分布的情况下,用均值和方差来表示。正则化项表示如下:
和项看起来要用到训练集的图像,但是作者巧妙地用第l层feature map对应的BN层的running_mean和running_variance作为这两项的估计。
总体上,DI的正则化约束为:
看起来思路也挺简单的,这种图像合成方法在对抗样本等领域也有应用。
Adaptive DeepInversion
ADI又在DI的基础上,引入了图像合成和student network训练两过程的竞争(称为迭代可能更好),主要步骤包括:
(1) 用DI生成部分图像。
(2) 用生成的图像训练蒸馏的student network.
(3) 固定student network,DI基础上计算项,生成部分图像。
(4) (2)(3) 步骤迭代。
其中 的定义如下式:1- teacher和student输出对分数(output distribution)的JS距离。
ADI的主要思路如下图所示:
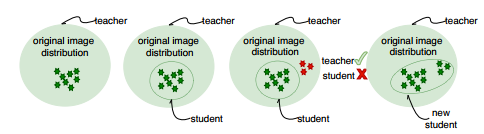
为什么ADI可以提升合成图像的多样性?通过DI合成的图像是原训练集的子集,而student network可以很好地捕捉这部分子集的分布。通过ADI方法生成图像处于原有子集之外,而student network进一步也将这一部分子集分布进行捕捉,最终会收敛到student network和teacher network建模的分布相等,合成的图像也分布在整个分布间,多样性提高了。
ADI在DI的基础上又更改了正则化项为:
实验和Data-Free应用
实验中,作者在CIFAR10和ImageNet两个数据集上做了对比实验,主要检测student network的分类正确率和合成图像的质量。
结果上:
CIFAR10上主要是正则化项的选取的对比实验。
BaseLine包括:
- (1)不添加正则化项;
- (2)DeepDream的正则化项配置;
- (3)DeepInversion;
- (4)ADI。
结果发现训练在合成图像上的student network的分类准确率上,(1)(2)几乎没有效果,而(3)提升40%-69%,(4)比(3)提升1%-10%。合成的图像质量看上去也更好。
ImageNet上
DI合成的图像具有泛化性:预训练的多种网络可以对他正确分类。图像质量上,取得了不错的IS scores(60.6)。
Data-Free 应用
Data-Free的应用基本思路是使用DI或者ADI合成图像替代原训练集图像蒸馏得到不同的student network。作者提及了pruning,knowledget-transfer,continual learning三方面的应用。
因为不是很了解Distilling,所以先鸽了。。