Preface
A Paper A Day Keep the Doctor Away. 今天的文章是:
Adversarial AutoEncoders. [paper]
本文就是有名的AAE模型,对AutoEncoder加入Adversarial Regularization,将它变成了生成模型。本文借鉴了VAE的思路扩展AutoEncoder,同时借鉴GAN的思路促使合计后验和期望先验的prior match。
Main Contents
Notion
先定义下说明的符号:
: desired prior。: encoding distribution。: decoding distribution。: data distribution。: model distribution。: aggregate posterior(合计后验),
Basic Model
基本的AAE模型如下:
图1中灰色线包括的区域是一个标准的AutoEncoder结构,Encoder对所有的输入可以得到隐编码的合计后验。而图中红色线包括的区域就是一个GAN,Generator就是AutoEncoder的Encoder,而Discriminator负责鉴别样本(隐编码)是来自于推断的合计后验(负样本)还是给定的先验(正样本),目的是优化。
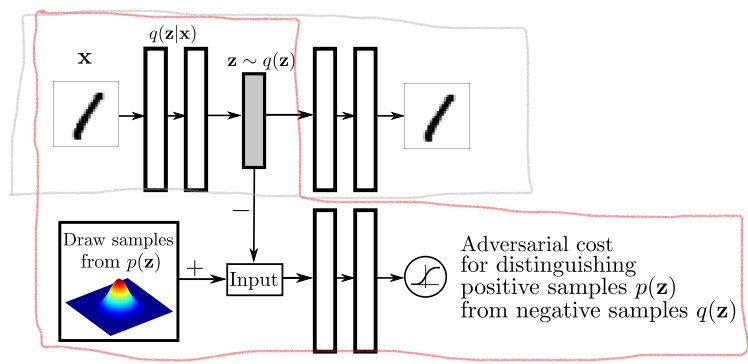
整体模型训练分为两个阶段:(1) reconstruction phase; (2) regularization phase。 其实就是分别训练AutoEncoder和GAN。GAN的训练又分为先训练D,再训练G。
Choices of Encoder
Encoder的选择有三种方式:
(1) Deterministic: 原始Encoder,此时的随机性来源于。
(2) Gaussian Posterior: 和VAE一样,,同时训练时使用重参数化,此时的随机性来源于的采样和
(3) Universal approximator Posterior:
Intuition
从一个直观的角度理解AAE:AutoEncoder已经可以做图像的编码、解码(生成),但是我们无法知道AutoEncoder编码的(AE不关心这一点),也很难从中采样。AAE就是希望使得的形式接近一个期望的,好让我们可以在中采样,使用解码器生成图像。
从和VAE的关系上说,VAE的ELBO的相反数为:
AAE的作用其实就是将上述分解的后两项替换成了另外一个促进匹配的形式,用adversarial tranining优化二者的JS距离。
Adaptive Models
作者针对不同任务和监督信息对AAE进行扩展。
Fully Supervised
在有监督信息(labels)的情况,扩展:
1. Label-Conditional Generation
Conditional版本的AAE,和CGAN,CVAE的目的一样,可以控制生成的图像类别,而且是fully-supervised。
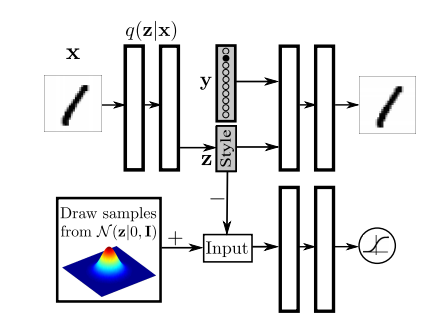
思路是将监督的label信息单独输入Decoder(Generator)中,而Encoder的仅编码和label信息独立的其他信息(称为Style)。GAN的部分不变。
Semi-Supervised
半监督下,扩展:
1. Incorporating Label Information
目的是,使得Latent space的编码和label对齐,对隐表示进行正则化:使用十个2-D混合高斯作为先验,使得每一个高斯可以对应一个class的编码。
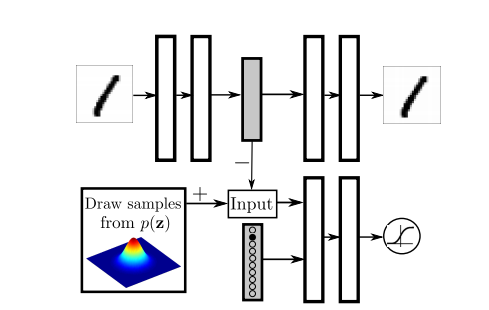
思路是将监督信息(onehot)单独输入Discriminator中,使得Discriminator可以针对不同的class判别和的距离。AutoEncoder的部分不变。
除此之外,作者还将无标注类作为独立的一类,希望对于该类,Discriminator会针对整体分布进行判别。
训练时,使用正样本(采样自)训练时,将采样的mixture component的编号onehot后输入。使用负样本(来自AutoEncoder)训练时,使用 label。
注意:该方法和上节的模型不同,本节的模型注重的是促进模型隐编码的结构。不过具体怎么个不同可能还需要数学上的分析。
2. Semi-Supervised AAE
将AAE扩展到Semi-supervised Learning,通过已有的标注label,模型预测未标注的label,提高分类准确性。
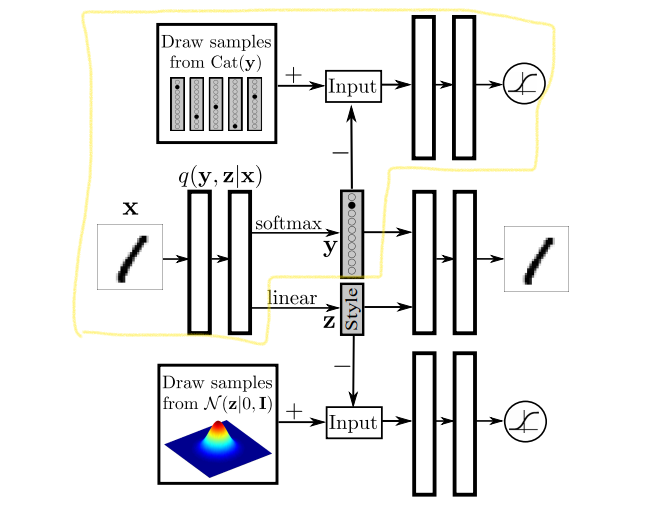
模型的思路是:希望从图像中学习到class编码信息,假定隐编码中的编码class信息,它的先验服从一个范畴分布(Categorical Distribution),而其余的先验服从标准高斯,编码其余的Style信息。
引入编码的学习,模型就必须引入另一对GAN优化和的距离,即途中黄线围绕区域。
模型训练分为三个阶段:(1)reconstruction phase:训练AutoEncoder; (2)regularization phase:分别对两个GAN训练;(3)semi-supervisd classification phase:利用有标注的数据,单独训练Encoder的y输出,该部分是Categorical GAN的Generator部分,也可以看成分类器。
Unsupervised
1. Unsupvervised Clustering
针对的是图像中离散数据、连续数据的Disentangled隐表示学习的问题。
模型和图4一样,图4的模型已经可以分别建模离散和连续的隐分量。只是去除了训练的 semi-supervised classification阶段。
Dimensionality Reduction
针对高维数据的降维任务,用于高维数据的可视化。 本身AutoEncoder也可以做,但是无正则化的AutoEncoder会遭遇“fracture”问题:将流形上靠近的图像映射到隐空间差异很大的区域,也就是相似图像在隐空间的编码却不相近。
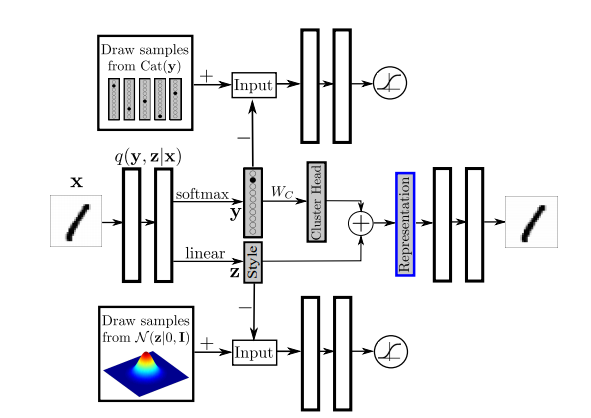
更具体点,任务是将类的样本降至类,方便可视化。
设计模型如图5,欲降至维,最终的表示由维的cluster head和维的隐编码相加而成。 cluster head是维的onehot输出乘以一个矩阵得到,也是可学习的参数。
除此之外,作者还加入了一个额外的cost function惩罚任意两个cluster head的欧式距离。
总结
总的来说,AAE引入对抗训练使得达到prior match效果,扩展了VAE的先验分布形式,并且避免了intractable问题。VAE的先验分布修改要重新修改重参数化等,比较麻烦,而AAE像是提供了一个framework。不过不可避免的是,AAE肯定比VAE难训练,毕竟加入了GAN嘛。