近来在 coding 中遇到特征图可视化的问题,最终考虑使用 CAM 类的方法,本文主要记述下原理、实现过程遇到的问题以及一些心得。
CAM(Class Activated Mapping)是一类可视化的方法,虽然最早用于对分类模型进行特征可视化,但是也可以扩展到 其他特征的可视化,这一类方法主要包括以下工作:
Grad-CAM
Grad-CAM++
XGrad-CAM
Eigen-CAM
balabala…
现在只用到了 Grad-CAM,但是感觉没达到预期的效果,后面用到再补上其他方法的坑。 用Pytorch实现各类 CAM 方法的一个很好的 repo: CAM Methods in Pytorch 。
Grad-CAM 的原理很简单:
假设 A {A} A y {y} y y {y} y
w k = 1 M × N ∑ i ∑ j ∂ y ∂ A i , j k {
w_k = \frac{1}{M \times N} \sum_i \sum_j \frac{\partial y}{\partial A_{i,j}^{k}}
} w k = M × N 1 i ∑ j ∑ ∂ A i , j k ∂ y
H i , j = ReLU ( ∑ k w k A i , j k ) {
H_{i,j} = \text{ReLU}\left( \sum_{k}{w_k A_{i,j}^{k}} \right)
} H i , j = ReLU ( k ∑ w k A i , j k )
整个计算过程简单来说就是: 首先标量 y 对目标特征图的梯度,然后梯度在空间尺度求平均,得到 channels 数量相等的 weights 向量, 用该向量对原始目标特征图进行 channel-wise 的加权和,最后 ReLU(过滤掉对 scores 影响为负的部分)。
更简单地总结成一句话就是:热力图是特征图在通道维度的加权和,而不同通道的权重是该通道梯度的平均。
实际上,所有的 CAM 方法的不同之处在于后半段话,也就是怎么计算通道的权重。(看了一些代码得到的结论,不过待验证)。
方法本身是很好理解的,实现起来也很简单,但是实际实现起来让我比较头疼的反倒是准备工作,通过研读之前提到的 repo 确实解决了我的两个疑问:
在 model 的 eval 模式下计算梯度:一般来说只会在 train 模式下计算模型的梯度,但可视化显然是在 eval 模式下进行。
model forward 中间计算结果的 feature map A {A} A
首先 eval 模式肯定是可以求梯度的,毕竟不是在 torch.no_grad() 的上下文下,只是因为所有的输入和权重的 Tensor 都设置了 requires_grad=False, 输出才没有 grad_fn 不能够求导;在 forward 过程中,只要计算过程中使用到一个需要求导的 Tensor,后续的输出都会变成可求导的,于是 repo 里将输入的 Tensor 改为 requires_grad=True,输出就是可以求导的(参考这一行 )。
对目标特征求梯度,本来我是用到 autograd.grad 的方式计算,但是实现上为了得到 model 前向和反向中特征 A {A} A 这里 。
不过 Grad-CAM 最后还是没有达到我想要的效果,采用了一种不同方式,这里就不提了,除此之外实验中发现 ReLU 其实很重要, 有些情况下,只有用 ReLU 过滤掉对梯度负影响的部分,最终的热力图才能达到想要的效果。ReLU的位置也有一定的影响,可以按需调整。
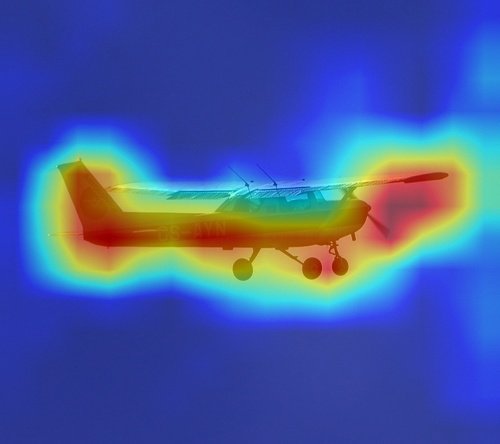
以下是对 ResNet50 的可视化的 demo。 ResNet50 使用 Pytorch 提供的 ImageNet 上的预训练模型, 输入图像是随便选的 VOC2012 的一张图。不得不说使用上面 repo 的实现技巧,代码简洁美观了很多。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 """ implement Grad-CAM samples on classification task """ import osimport numpy as npimport torchimport PIL.Image as Imageimport cv2from torchvision.models.resnet import resnet50import torchvision.transforms as Tdef min_max_rescale (x) : return (x - x.min()) / (x.max() - x.min()) def load_input (do_transform=True) : transform = T.Compose([ T.ToTensor(), T.Normalize( mean=[0.485 , 0.456 , 0.406 ], std=[0.229 , 0.224 , 0.225 ] ) ]) root = "/home/victorchen/workspace/Venus/VOCdevkit/VOC2012/JPEGImages" name = "2008_000037.jpg" img_path = os.path.join(root, name) img = Image.open(img_path) if do_transform: timg = transform(img) else : timg = img return timg, img_path, name class ActivationsAndGradients : """ Class for extracting activations and registering gradients from targetted intermediate layers. from https://github.com/jacobgil/pytorch-grad-cam/blob/3014beaf2877e621e686e5afe7f718c01f1a74d5/pytorch_grad_cam/activations_and_gradients.py#L1 """ def __init__ (self, model, target_layers, reshape_transform) : self.model = model self.gradients = [] self.activations = [] self.reshape_transform = reshape_transform self.handles = [] for target_layer in target_layers: self.handles.append( target_layer.register_forward_hook(self.save_activation)) self.handles.append( target_layer.register_forward_hook(self.save_gradient)) def save_activation (self, module, input, output) : activation = output if self.reshape_transform is not None : activation = self.reshape_transform(activation) self.activations.append(activation.cpu().detach()) def save_gradient (self, module, input, output) : if not hasattr(output, "requires_grad" ) or not output.requires_grad: return def _store_grad (grad) : if self.reshape_transform is not None : grad = self.reshape_transform(grad) self.gradients = [grad.cpu().detach()] + self.gradients output.register_hook(_store_grad) def __call__ (self, x) : self.gradients = [] self.activations = [] return self.model(x) def release (self) : for handle in self.handles: handle.remove() save_root = "exps/vis" os.makedirs(save_root, exist_ok=True ) device = torch.device("cuda:0" ) model = resnet50(pretrained=True ).to(device) model.eval() model_forward = ActivationsAndGradients(model, [model.layer3, model.layer4], None ) images, path, name = load_input() images = images.to(device).unsqueeze(dim=0 ) images.requires_grad_(True ) scores = model_forward(images) scores = torch.softmax(scores, dim=1 ) target_score = scores.max() print(target_score) target_score.backward(retain_graph=True ) feat_names = ["feat_res3" , "feat_res4" ] feats = model_forward.activations gradients = model_forward.gradients for fname, feat, grad in zip(feat_names, feats, gradients): grad_weights = grad.mean(dim=[-1 , -2 ], keepdim=True ) heatmap = torch.relu((grad_weights * feat).sum(dim=1 )) heatmap = heatmap[0 ].detach().cpu().numpy() img = cv2.imread(path) height, width = img.shape[:2 ] heatmap = min_max_rescale(heatmap) heatmap = np.clip(heatmap, 0.0 , 1.0 ) * 255.0 heatmap = heatmap.astype(np.uint8) heatmap = cv2.resize(heatmap, dsize=(width, height)) heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET) alpha = 0.6 img = img * (1 - alpha) + heatmap * alpha img = img.astype(np.uint8) save_img_path = os.path.join(save_root, f"{fname} _{name} " ) cv2.imwrite(save_img_path, img)
实际看出对 C4 可视化的效果并不太好,一方面可能是因为 trainset 和 testset 不太符合,另一方面我感觉可能对极度非线性的函数,Grad-CAM 效果会较差。C5 特征到最终 score 的映射就是比较线性的。